🫨 바이브 코딩은 죽었다.
1. 바이브 코딩 (Vibe Coding)
‘바이브 코딩 (Vibe Coding)'이 2025년을 휩쓸었습니다. 영국의 유명 사전 중 하나인 Collins 사전에서는 ‘바이브 코딩’을 2025년 올해의 단어로 선정했습니다.

바이브 코딩 (Vibe Coding)은 대규모 언어 모델(LLM), 예를 들어 ChatGPT 같은 AI를 활용해서 사람과 AI가 대화하듯 코드를 만들고 수정하는 새로운 코딩 방식입니다. 아마 많은 분들이 이미 자연스럽게 이런 식으로 코딩하고 계실 겁니다.
이 용어는 OpenAI의 창립 멤버이자 테슬라 오토파일럿을 이끌었던 안드레 카파시가 Andrej Karpathy on Twitter / X 에서 처음 사용했습니다. 말 그대로 코드는 잘 모르겠고, ‘느낌대로’ 코딩 한다는 뜻입니다.
1.1. LLM의 발전이 바꾼 코딩 풍경
불과 2년 전(2023년)만 해도 LLM의 성능이 지금처럼 뛰어나진 않았습니다. 저도 당시 ChatGPT에게 코딩 관련 질문을 하면, 꽤나 "멍청한 답변"을 받기 일쑤였습니다. 그래서 AI를 코딩에 제대로 활용하기 어려웠습니다.
하지만 이후 LLM의 성능이 비약적으로 발전했습니다. 이제는 사람이 복잡한 요구사항을 질문하면, AI가 곧바로 아주 그럴듯하고 쓸만한 답변을 내놓을 수 있게 되었습니다. 덕분에 많은 개발자와 일반 사용자들까지 ChatGPT 같은 도구를 이용해 AI와 대화하듯 질문하고, 그 결과로 코드를 얻어내는 '바이브 코딩'을 시작하게 된 것입니다.
→ 코딩이 훨씬 쉽고 직관적으로 바뀐 셈입니다.
하지만 매번 코드 에디터의 코드를 복사하고 ChatGPT에게 붙여넣기 하고 나온 결과를 다시 코드 에디터에 붙여넣기 하는 등 번거로움이 많았습니다.
바이브 코딩이라는 새로운 방식이 개념으로만 머무르지 않고 실제 개발 환경으로 빠르게 퍼져나갈 수 있게 만든 주역이 있습니다. 바로 'Cursor'라는 혁신적인 코드 에디터입니다.
(Fun Fact: 이 Cursor의 엄청난 성장세 때문에 OpenAI가 Cursor와 비슷한 IDE인 Windsurf 라는 코드 에디터를 4조 2천억에 인수하려다가 Google DeepMind가 Windsurf의 기술 라이센스 및 CEO, 핵심 개발자들을 3조 3,600억에 데려갔습니다.)
1.2. Cursor: AI를 위해 태어난 Editor
Cursor는 말 그대로 'AI를 최우선으로 생각하는(AI-first)' 코드 에디터로 유명해졌습니다. 많은 분들이 사용하시는 VS Code를 기반으로 만들어져서 사용법이 낯설지 않으면서도, 바이브 코딩을 가장 쉽고 강력하게 할 수 있도록 설계되었습니다.

Cursor의 핵심은 'AI와의 대화' 기능을 에디터 내부에 완벽하게 통합했다는 점입니다.
- 코드 옆에서 바로 대화: 개발자는 코드를 보면서 에디터 하단이나 옆에 있는 채팅창에 곧바로 AI에게 명령을 내릴 수 있습니다.
- 질문이 곧 코딩: "이 함수에 로그인 기능을 추가해 줘" 또는 "여기서 발생하는 Null 에러를 수정해 줘"처럼 일상적인 대화나 질문을 입력하면, AI가 곧바로 해당 코드를 분석하고 수정하거나 새로운 코드를 생성해 줍니다.
1.2.1. 바이브 코딩을 대중화시키다
Cursor의 등장 덕분에 "느낌대로 코딩한다"는 바이브 코딩이 단순한 유행을 넘어, 수많은 개발자의 일상적인 코딩 방식으로 빠르게 자리 잡게 되었습니다.
Cursor는 AI를 코딩 과정에서 보조적인 도구가 아닌, 대화하며 코드를 함께 만들어가는 파트너로 격상시켰습니다. 이제 개발자는 복잡한 구문이나 검색에 시간을 낭비하는 대신, '무엇을 만들지'에 집중하고 AI와 대화하며 코드를 완성하는 효율적인 시대를 맞이하게 된 것입니다. 바이브 코딩의 대중화에 가장 크게 기여한 도구가 바로 Cursor라고 할 수 있습니다.
Cursor와 같은 AI 코딩 도구가 인기를 끌면서, Cursor와 같은 소프트웨어를 제대로 사용하기 위해 개발자들에게 새로운 숙제가 생겼습니다. 바로 "질문을 잘하는 능력"입니다.
2. Prompt Engineering

2.1. Garbage In, Garbage Out
바이브 코딩은 AI와의 대화가 곧 코딩이 되는 방식입니다. 여기서 핵심 원칙은 컴퓨터 과학에서 오래된 격언인 "Garbage In, Garbage Out (GIGO)"이 그대로 적용됩니다.
- Garbage In (엉망인 입력): 만약 AI에게 모호하거나, 불분명하거나, 충분한 정보가 없는 질문을 던지면,
- Garbage Out (엉망인 출력): AI는 개발자가 원하는 바를 정확히 알 수 없어 엉뚱하거나, 쓸모없거나, 에러투성이인 코드를 만들어내기 쉽습니다.
2.2. Prompt Engineering: AI 코딩의 핵심 스킬
이처럼 AI에게 명확하고 효과적인 질문이나 지시(Prompt)를 전달하는 기술을 프롬프트 엔지니어링(Prompt Engineering)이라고 부릅니다. 이는 바이브 코딩 시대에 개발자들이 반드시 갖춰야 할 핵심 스킬이 되었습니다.
좋은 프롬프트는 단순히 "로그인 코드 만들어 줘"가 아니라, 다음과 같은 구체적인 정보를 포함합니다.
- 역할 부여: "너는 숙련된 Go 개발자야."
- 맥락 제공: "이전 코드를 참고해서, 지금 이 함수에 코드를 추가할 거야."
- 구체적인 요구사항: "Gin 프레임워크를 사용하고, 사용자 인증은 OAuth 2.0으로 해줘."
- 출력 형식 지정: "주석을 자세히 달고, 예외 처리도 꼭 해줘."
프롬프트 엔지니어링을 잘하는 사람은 AI를 단순한 코드 생성기가 아닌, 최고의 코딩 조교로 활용하여 빠르고 정확하게 원하는 결과물을 만들어낼 수 있습니다.
2.3. Prompt Engineering의 한계: 그런데!! 왜 질문만 잘해서는 안 되는가?
저는 사이드 프로젝트로 Next.js를 이용한 ‘바이브 코딩’을 해본 적이 있습니다. Next.js를 전혀 몰랐던 상태였기에, 말 그대로 감(바이브)에 의존한 코딩이었습니다.

바이브 코딩을 해보니, 그럴듯한 프로토타입과 프로젝트의 시작점은 빠르게 만들어주지만, 규모가 커질수록 문제가 드러났습니다. 제 기준에서는 좋은 질문을 했다고 생각했는데, 잘못 수정된 코드를 반복해서 같은 방식으로 잘못 수정하는 경향이 있었습니다.
프롬프트 엔지니어링(Prompt Engineering)은 바이브 코딩의 필수 스킬이지만, 이것만으로는 복잡하고 대규모인 실제 개발 환경을 감당하기 어렵습니다. AI에게 '좋은 질문'을 던지는 것과 '좋은 코드를 얻는 것' 사이에는 분명한 간극이 존재합니다.
‘좋은 질문’을 했다고 가정해봅시다. 그런데 아무리 질문을 잘해도, AI는 개발자가 현재 작업 중인 전체 코드의 맥락(Context)을 한 번에 완벽하게 이해하기 어렵습니다. 그 이유는 다음과 같습니다.
- 짧은 기억력: LLM은 대화창에 입력된 내용만 기억합니다. 개발자가 한참 전에 작업했던 파일, 프로젝트 전반의 아키텍처, 팀이 정한 코딩 규칙 등 넓은 맥락 정보가 없으면 AI는 이를 무시하고 코드를 생성합니다. (많이 개선되었다고는 하나 아직까지 제한이 있습니다.)
- 부분 최적화: AI는 현재 프롬프트에 주어진 요구사항만 충족시키는 코드(Local Optimization)를 만들려는 경향이 있습니다. 그 결과, 프로젝트 전체의 구조와 조화롭지 않고 독립적으로 작동하는 코드 덩어리를 만들게 됩니다.
- 새로운 레거시: 이렇게 만들어진 코드는 당장은 작동할지라도, 나중에 다른 개발자가 이해하고 수정하기 어려운 '새로운 레거시 코드(Legacy Code)'가 될 위험이 높습니다.
→ 바이브 코딩이 오히려 장기적으로 프로젝트의 유지 보수를 어렵게 만든다는 비판이 나오는 이유가 여기에 있습니다.
즉, 바이브 코딩과 프롬프트 엔지니어링으로 그럴듯한 결과는 얻을 수 있지만 여러 사람이 협업하는 큰 프로젝트에서는 부적합합니다.

그리고 최근 프롬프트 피로감이라는 용어가 등장했습니다. 아무리 정교한 프롬프트를 작성해도 AI가 일관성 있는 결과를 내지 못하고, 매번 새로운 대화에서 처음부터 설명해야 하는 번거로움이 계속되었습니다.
3. Context Engineering
허깅 페이스 테크 리더이자 현재 구글 딥마인드에서 엔지니어로 일하고 있는 필립 슈미트가 기고한 글 “AI에서 새로운 스킬은 프롬프트가 아니라 컨텍스트 엔지니어링”이라고 해서 상당히 화제를 일으킨 적이 있습니다.
- 먼저 Shopify의 CEO가 tobi lutke on Twitter / X 트윗을 하며 널리 퍼져나갔습니다.
앞서 바이브 코딩이라는 용어를 처음 만들었던 안드레 카파시도 이제는 "Prompt Engineering" 대신 "Context Engineering"을 지지하며 Context Engineering을 강조했습니다.
3.1. Context
그럼 Context란 무엇일까요? Context란 쉽게 말해서 프롬프트 엔지니어링을 포함하여 상태/이력 (단기 메모리), 장기 메모리, 검색된 정보 (RAG), 사용 가능한 도구들, 구조화된 출력을 포함한 것입니다.
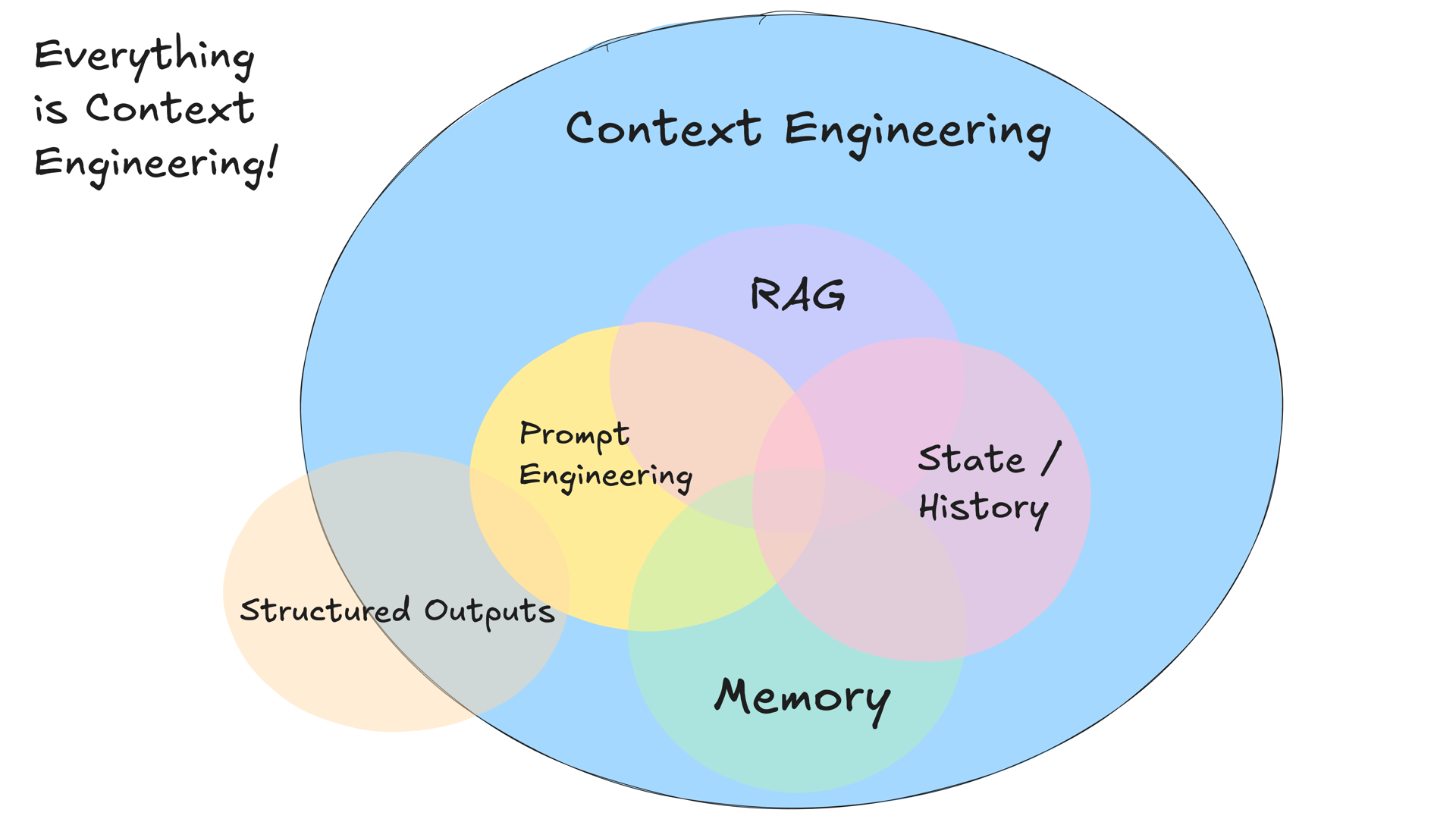
3.2. Context Engineering
컨텍스트 엔지니어링은 AI가 코드를 생성하거나 수정할 때, 개발자가 직접 언급하지 않아도 프로젝트의 전체적인 맥락(Context)을 자동으로 이해하고 활용하도록 만드는 과정입니다.
단순히 질문(프롬프트)에만 의존하는 것이 아니라, AI 자체가 프로젝트의 '개발 환경' 내부로 깊숙이 들어와 모든 정보를 파악하게 만드는 것입니다.
즉, Prompt Engineering이 “좋은 답변을 얻기 위해 무엇을 말할까?”에 집중한다면, Context Engineering은 “LLM이 모든 사실, 규칙, 문서, 계획, 도구를 아우르는 전체 맥락 생태계를 갖도록” 시스템을 설계합니다.
3.3. 왜 컨텍스트 엔지니어링이 미래인가?
컨텍스트 엔지니어링은 LLM의 '기억력' 한계를 뚫고, AI를 단순한 코드 조각 생성기에서 프로젝트의 구조를 이해하는 '유능한 중니어 개발자' 수준으로 끌어올립니다.
이를 통해 개발자는 대규모 프로젝트에서도 '느낌대로' 대화만 하면, AI가 필요한 모든 맥락을 스스로 파악하여 품질 높은 통합 코드를 제공받을 수 있게 됩니다. 바이브 코딩이 실제 산업 현장에서 강력한 힘을 발휘하기 위한 필수적인 진화인 셈입니다.
컨텍스트 엔지니어링의 목표는 AI에게 필요한 모든 맥락을 제공하는 것입니다. 하지만, 수많은 파일과 복잡한 구조를 가진 프로젝트에서 AI가 '알아서' 모든 것을 이해하도록 만드는 것은 어렵습니다.
이 문제를 근본적으로 해결하고, AI가 일관성 있고 품질 높은 코드를 생성하도록 돕는 필수적인 방법론이 바로 명세 기반 개발(Spec-Driven Development, SDD)입니다.
4. Spec-Driven Development (SDD)
4.1. 요구사항부터 설계 및 작업 목록까지 AI가 이해하는 언어로
SDD는 개발 프로세스의 시작점을 명확하고 구조화된 명세(Specification)로 정의합니다. 기존 개발 과정에서 사람이 손으로 만들던 요구사항 명세서, 설계 문서, 작업 계획 등을 AI가 쉽게 이해하고 활용할 수 있는 형태로 자동화하는 것을 목표로 합니다.
4.1.1. Kiro
이 SDD를 가장 쉽게 도와주는 소프트웨어가 AWS에서 개발한 Kiro 입니다. 전 당시 Claude의 Sonnet 4.0을 무료로 계속 사용할 수 있다고 해서 베타 테스트 기간 부터 2개월 전까지 이용해 왔었습니다.

Kiro에서는 AWS의 설계 철학 및 개발 방법론대로 다음 과정을 통해 SDD를 실현합니다.
- Requirements: 모호성을 없애는 구조화된 요구사항
- AI가 훌륭한 코드를 만들려면, 요구사항 자체가 모호해서는 안 됩니다. 요구사항을 단순히 글로 나열하는 대신, 세부 요구사항과 승인 기준(Acceptance Criteria)이 명확하게 정리된 구조를 사용합니다.
명확한 구조 및 EARS 기법 활용
- 명확한 구조: 생성된 명세는 마치 Jira와 같은 작업 관리 도구의 티켓처럼, 사용자 스토리(User Story) 아래에 구체적인 WHEN, IF, THEN과 같은 형식으로 정리됩니다.
- EARS 기법 활용: 이 방식은 기업 환경에서 널리 사용되는 EARS (Easy Approach to Requirements Syntax)라는 요구사항 작성 기법을 따릅니다. EARS를 사용하면 문장이 표준화되어 AI 모델이 요구사항을 훨씬 더 정확하게 이해할 수 있습니다. 그 결과, AI는 프롬프트의 해석과 코드 생성 반응이 한층 더 정밀해집니다.
- 예: 특정 사건(Event-Driven)이나 상태(State-Driven)에 따라 요구되는 기능을 명확히 구분합니다.
- AI가 훌륭한 코드를 만들려면, 요구사항 자체가 모호해서는 안 됩니다. 요구사항을 단순히 글로 나열하는 대신, 세부 요구사항과 승인 기준(Acceptance Criteria)이 명확하게 정리된 구조를 사용합니다.
- Design: 요구사항 기반의 자동 설계 문서화
- 요구사항이 확정되면, 이를 기반으로 시스템이 실제로 어떻게 구현될지를 구체화하는 설계(Design) 단계로 넘어갑니다. 이 단계에서는 AI가 기술 구조, 데이터 흐름, 모듈 간 관계 등 구현 시 고려해야 할 사항을 자동으로 문서화합니다.
아키텍처 개요 및 요구사항 명세
- 자동 생성 범위: 아키텍처 개요, 데이터 흐름 다이어그램(DFD), 인터페이스 정의, 데이터베이스 스키마(DDL 초안), API 엔드포인트 스펙 초안 등이 자동으로 생성됩니다.
- 일관성 유지: 가장 큰 장점은 요구사항 명세와 설계 산출물이 서로 연결되어 있다는 것입니다. 요구사항이 변경되면 설계 문서도 자동으로 갱신되어, '요구사항 → 설계 → 구현' 간의 불일치(Inconsistency)를 최소화하고, AI에게 항상 최신의 정확한 컨텍스트를 제공합니다.
- 요구사항이 확정되면, 이를 기반으로 시스템이 실제로 어떻게 구현될지를 구체화하는 설계(Design) 단계로 넘어갑니다. 이 단계에서는 AI가 기술 구조, 데이터 흐름, 모듈 간 관계 등 구현 시 고려해야 할 사항을 자동으로 문서화합니다.
- Task List: 종속성을 고려한 작업 계획
- 마지막으로 SDD는 프로젝트 진행에 필요한 작업(Task)과 하위 작업(Sub-task)을 자동으로 생성합니다.
종속성 및 테스트를 포함한 Task
- 종속성 기반 순서: 각 작업의 순서는 종속성(Dependency)을 기반으로 정확하게 배치되어, 어떤 작업을 먼저 해야 하는지 명확한 가이드를 제공합니다.
- 품질 기준 포함: 각 작업은 해당 요구사항과 직접 연결되어 있을 뿐만 아니라, 단위 테스트 항목, 통합 테스트 항목, 모바일 반응성 요구사항 등 품질 기준과 구현 가이드까지 함께 제공합니다.
- 마지막으로 SDD는 프로젝트 진행에 필요한 작업(Task)과 하위 작업(Sub-task)을 자동으로 생성합니다.
4.1.2. BMad Method
사실 Kiro가 유명해지기 전부터 Spec Driven Development를 계속해서 주장하던 개발자가 있었습니다. 브라이언 매디슨은 20년 이상의 경력을 가진 소프트웨어 엔지니어 및 엔지니어링 리더로 미국 국방부 부터 시작해서 대기업, 신생 스타트업까지 폭넓게 근무한 개발자입니다.

이 개발자가 개발한 BMad Method는 AI 에이전트를 활용하여 프로젝트의 아이디어 구상부터 최종 코드 구현까지 소프트웨어 개발 수명 주기(SDLC)를 체계적으로 진행하는 방법론입니다.
프로젝트를 처음부터 끝까지 구성하는 핵심 흐름은 다음과 같은 에이전트 중심의 단계로 진행됩니다.
- 분석가 (Analyst)
- 프로젝트 아이디어에 대한 초기 브레인스토밍을 수행하고, 아이디어를 구체화하여 프로젝트 목표를 정의합니다. 브레인스토밍, 마켓 리서치, 경쟁사 분석, 제품 요약을 바탕으로 PRD(Product Requirements Document)를 작성합니다.
- 설계자 (Architect)
- PRD의 요구사항을 기반으로 기술 스택, 시스템 구성 요소, 데이터 모델, 코드 구조 등 프로젝트의 기술적 청사진을 설계합니다. 이를 통해 Architecture 문서를 생성합니다.
- 제품 관리자 (Proudct Manager)
- PRD와 Architecture 문서를 바탕으로 기능(FRS; Functional Requirements Specification) 및 비기능적(Non-FRS) 요구사항을 정의하고, 이를 에픽(Epic)과 사용자 스토리(User Story)로 세분화하여 MVP(Minimum Viable Product) 범위를 확정합니다.
그 외 단계
- 스크럼 마스터 (Scrum Master)
- PRD와 아키텍처 문서를 기반으로 각 사용자 스토리를 개발자가 즉시 구현할 수 있도록 매우 상세하고 구체적인 개발 스토리 파일로 변환합니다.
- 문서 분할 (Sharding)
- 프로젝트 전체 문서를 작은 단위(예: 섹션별)로 분할하여 개발 에이전트가 필요할 때 관련 컨텍스트만 로드하도록 최적화합니다.
- 개발자 (Developer)
- 스크럼 마스터가 작성한 스토리 파일을 입력받아, 스토리의 세부 작업(Tasks)을 순서대로 진행하며 실제 코드를 구현하고 파일을 생성/수정합니다.
- QA
- 개발이 완료된 스토리와 생성된 코드를 검토하여 요구사항 및 아키텍처 준수 여부, 잠재적인 오류나 개선점을 식별하고 검증합니다.
BMad Method의 가장 중요한 특징은 단순히 AI에게 작업을 던지는 것이 아니라, 고급 유도 기법을 사용하여 에이전트가 자체적으로 비판적 사고, 위험 분석, 대체 솔루션 탐색 등을 수행하도록 유도하는 것입니다. 이를 통해 개발자는 AI와의 상호작용을 통해 더 나은 품질의 결과물을 얻을 수 있습니다.
4.1.3. Spec Kit
GitHub이 개발한 Spec Kit은 AI 기반 개발 환경에서 Spec-Driven Development(명세 주도 개발)를 시작하도록 돕는 오픈 소스 툴킷입니다.

Spec Kit의 목표는 기존 개발 방식(코드가 중심)에서 벗어나 "명세(Specification)가 실행 가능한 코드와 구현을 직접 생성"하도록 설계된 새로운 개발 방법론을 지원하는 것이 핵심 목표입니다. 즉, 코드가 아닌 명세가 Source of Truth 입니다.
Spec Kit은 일련의 명령어들을 제공하여 SDD 워크플로우를 안내합니다. (다음은 Claude Code에서 명령할 수 있는 Spec Kit 명령어들 목록입니다; 이외에도 /speckit.clarify, /speckit.analyze 등의 명령어가 있습니다.)
| 원칙 수립 | /speckit.constitution |
프로젝트의 지배 원칙 및 개발 가이드라인(코드 품질, 테스트 표준, 성능 요구사항 등)을 생성하거나 업데이트합니다. 이는 모든 후속 개발의 기준이 됩니다. |
| 명세 생성 | /speckit.specify |
무엇을 만들고 왜 만드는지에 초점을 맞춰 애플리케이션 요구사항을 정의합니다. (기술 스택은 언급하지 않습니다.) |
| 기술 계획 | /speckit.plan |
선택한 기술 스택(Tech Stack)과 아키텍처 선택을 제공하여 기술적 구현 계획을 생성합니다. |
| 작업 분해 | /speckit.tasks |
구현 계획을 기반으로 실행 가능한 세부 작업 목록(Task List)을 생성합니다. |
| 구현 실행 | /speckit.implement |
생성된 작업 목록을 실행하여 계획에 따라 최종 기능을 구현하고 코드를 작성합니다. |
Kiro, BMad-Method, Spec Kit 등 결국 본질은 똑같습니다. SDD는 AI에게 '무엇을', '어떻게', '어떤 순서로', '어떤 품질로' 만들어야 하는지에 대한 완벽하고 구조화된 컨텍스트를 제공합니다.
이는 AI가 코드베이스 깊숙한 곳의 맥락까지 파악하여 레거시 코드를 만들지 않고 기존 시스템에 완벽하게 통합되는 고품질 코드를 생성할 수 있게 만드는 핵심 기반입니다.
4.2. BMad Method와 Spec Kit, 그리고 도메인 지식의 조합
Spec Kit을 사용해보면서 몇 가지 한계를 발견했습니다.
새로운 프로젝트를 시작할 때 Spec → Plan → Task 단계까지는 훌륭하게 만들어주지만, 정작 그 앞단 (이 프로젝트가 어떤 목적을 갖고 있고, 어떤 비즈니스 방향성을 가지며, 어떤 아키텍처 및 기술 스택이 필요한지, 어떤 기능 범위를 포함하는지)를 정의하는 PRD, Architecture, FRS는 생성해주지 않았습니다.
또한 BMad Method는 좋은 구조를 제공하지만, 명령어가 너무 많고 파편화되어 있어 실제 유저 입장에서는 사용하기에 어려울 것 같다는 생각이 들었습니다.
즉, 각 도구와 방법론이 제각각 흩어져 있어서 이를 하나의 흐름으로 묶고 최적화할 필요가 있었습니다.

그래서 이 문제를 해결하기 위해 여러 번의 실험과 시도를 거쳤고, 결국 다음과 같은 한층 더 완성된 프로세스를 설계할 수 있었습니다.
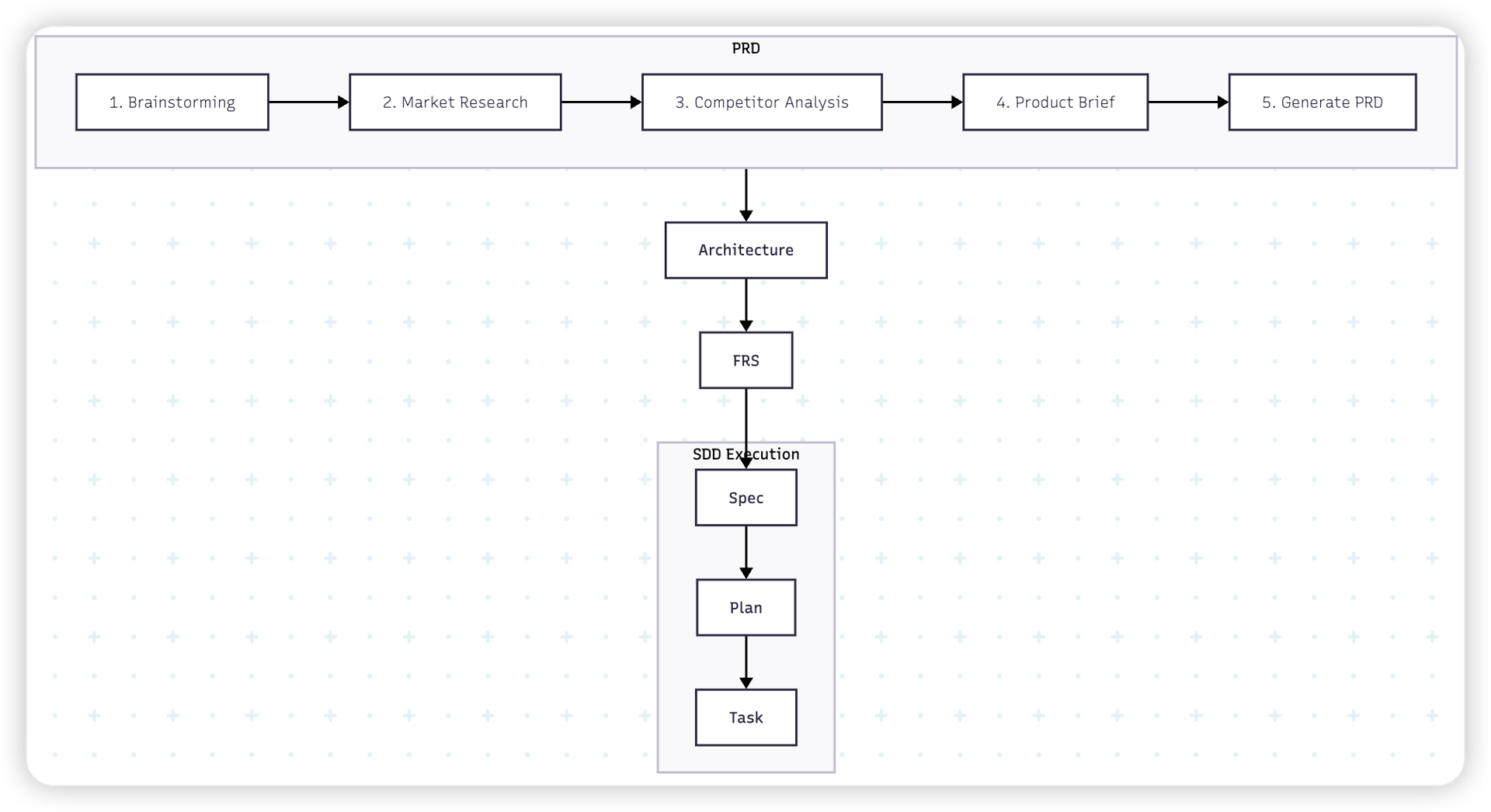
이 프로젝트를 진행하면서 질문했던 모든 프롬프트들을 인수인계 해야할까요? git 처럼 코드의 이력이 아닌 프롬프트를 이력으로 남기는게 말이 될까요? 만약 프롬프트 이력이 아닌 말이나 문서로써 인수인계 한다면 과연 그 인수인계가 제대로 될 수 있을까요?
우리는 프로젝트를 진행하면서 작성된 모든 과정들이 문서로써 정리되고, AI가 이력 관리 및 이해하기 쉬운 형태로 유산을 남겨야 합니다. 그럼 인계 받은 사람은 Task 목록들을 보면서 이 프로젝트가 어디까지 진행이 됐고, 어떤 과정들이 남았는지 쉽게 알 수 있을 것입니다.
즉, 우리는 돌아가는 소프트웨어를 만드는 것이 아니라 계속해서 살아서 발전하는 소프트웨어를 만들어야 합니다.
💬 Comments